Bạn có thể đọc bản gốc về định nghĩa, tính chất cũng như cách hoạt động Bloom filter (BF) tại đây. Tuy nhiên, do bản gốc có thể gây lạ lẫm với những người không liên quan đến IT, nên người viết sẽ cố gắng trình bày theo ngôn từ gần gũi hơn.
Trước khi đến với BF, chúng ta cùng tìm hiểu xem tính chất False positive là gì, vì đây là tính chất quan trọng, gắn chặt với BF.
Tính chất False positive (FP)
Khi ta đưa ra câu hỏi X, thì nếu như một thực thể đưa ra câu trả lời chỉ là X hoàn toàn không có (hoàn toàn phủ định) hoặc X có thể có (có khả năng), thì thực thể đó có tính chất FP.
Ví dụ, ta có câu hỏi: Trong rổ có quả bóng đỏ nào không?, mà câu trả lời nhận được là Hoàn toàn không có hoặc Có thể có, thì đây cũng thoả mãn tính chất của FP.
Nếu như câu trả lời không phải là hoàn toàn phủ định hoặc có khả năng, thì không thoả mãn tính chất FP. (Ví dụ như câu trả lời là: Chắc chắn có bóng đỏ trong rổ)
Do câu trả lời nhận được là có khả năng, nghĩa là FP không hoàn toàn chắc chắn (hoàn toàn khẳng định) với câu trả lời (ví dụ chắc chắn trong rổ có quả bóng đỏ), nghĩa là có những lúc bạn sẽ nhận được câu trả lời sai! (Ví dụ, trong rổ không có quả bóng đỏ nào, nhưng câu trả lời nhận được lại là có thể có bóng đỏ trong rổ). Vì vậy nó mới được gọi là False positive, tức là có thể sai trong trường hợp câu trả lời có tính khẳng định.
Bloom filter (BF) là gì?
Được nghĩ ra bởi Burton Howard Bloom vào năm 1970, BF là một cấu trúc dữ liệu cho phép xác định một phần tử E (element) có nằm trong tập cho trước S (set) hay không. Và BF thoả mãn tính chất FP, nghĩa là BF sẽ đưa ra câu trả lời dạng hoàn toàn phủ định hoặc có khả năng cho câu hỏi được đưa ra.
Nguyên tắc hoạt động
Để có thể đưa ra câu trả lời cho câu hỏi Có phần tử E trong tập S không?, thì với mọi phần tử của tập S, BF lưu giữ những đặc điểm của từng phần tử này.
Khi phần tử E được đưa cho BF, BF sẽ kiểm tra xem phần tử E này có đặc điểm nào trùng với những đặc điểm mà nó đang lưu giữ không. Nếu không có đặc điểm trùng, thì khẳng định chắc chắn là E không nằm trong tập S, ngược lại thì S có khả năng có chứa E.
Vậy, sẽ dẫn tới một số câu hỏi:
- Q: BF trích xuất đặc điểm của từng phần tử trong S và lưu trữ thế nào?
-
A: BF dùng những hàm băm (hash function) để lấy ra những đặc điểm của phần tử, và lưu giữ những đặc điểm này. Càng nhiều hàm băm thì cho tỉ lệ câu trả lời
hoàn toàn phủ địnhcàng chính xác (hay ngược lại là tỉ lệ câu trả lờicó khả nănglà sai càng thấp).Việc chứng minh phải dùng tới công thức tính xác xuất(có thể tham khảo mục
Probability of false positivesở đây), nhưng có thể hiểu nôm na là, khi càng dùng nhiều các hàm băm khác nhau, vậy ta sẽ có càng nhiều các đặc điểm khác nhau của phần tử đó. Như vậy, càng nhiều đặc điểm mà phần tử phải thoả mãn, thì tỉ lệ phần tử thoả mãn tất cả các điều kiện đó càng thấp. (Ví dụ, em gái tuyển người yêu với các tiêu chí (đặc điểm):đẹp trai, cao to nhà giàu, học Back Quoa, là dân ITthì sẽ có ít cơ hội hơn em gái chỉ tuyển với 1 tiêu chí là:Là dân IT.)(Trong chuyên ngành thực tế, BF dùng một mảng gồm m bits, và k hash functions, để tính toán và lưu trữ những “đặc điểm” của phần tử đó. Cụ thể:
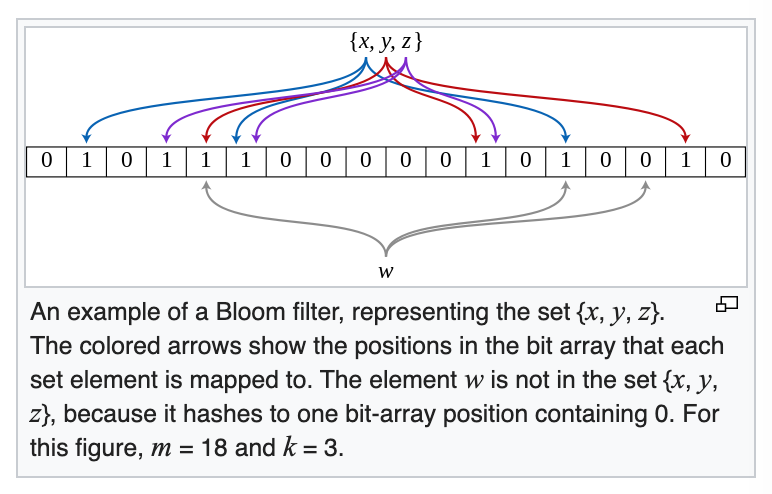
Ảnh: Wikipedia)
- Q: Tại sao lại là có khả năng có chứa? Chẳng phải E thoả mãn đặc điểm thì E sẽ nằm trong S hay sao?
- A: Tuy E thoả mãn điều kiện, nhưng có thể có trường hợp E’ khác (E’ khác E) cũng thoả mãn điều kiện, và S chứa E’ chứ không chứa E. Vậy nên không thể khẳng định chắc chắn là S chứa E được.
Ứng dụng dạng ý tưởng
Một công việc T có chi phí thực hiện lớn, thường sẽ được đặt sau BF để giảm chi phí cho yêu cầu không thoả mãn công việc T. Ví dụ, có 1 rổ gồm 1000 quả bóng, được đánh số ngẫu nhiên từ 1 đến 10.000. Giờ có yêu cầu, tìm quả bóng có đánh số X. Nếu làm theo cách thông thường, thì sẽ tìm lần lượt trong 1000 quả bóng đó, nếu có thì trả về quả bóng X, còn nếu ko có thì trả lời là không có. Rõ ràng là khá tốn công.
Có nhiều cách để tìm nhanh quả bóng, nhưng để liên quan đến bài viết, ta sẽ đặt trước rổ bóng một BF, và dùng hàm băm là: Là phần dư của X cho 10. Vậy với ví dụ: rổ có các quả bóng 1, 2, 11, ..., ta sẽ có:
1 / 10 = 0 dư 1
2 / 10 = 0 dư 2
11 / 10 = 1 dư 1
=> BF sẽ lưu trữ 1, 2 lần lượt là số dư các phép chia trên
- Nếu X = 3, ta có
3 / 10 = 0 dư 3, 3 không nằm trong số những số dư mà BF đang lưu giữ => kết luận luôn là bóng 3hoàn toàn khôngnằm trong rổ mà không cần tìm kiếm gì cả. - Nếu X = 21, ta có
21 / 10 = 2 dư 1, 1 nằm trong danh sách số dư, vậy kết luận là 21có khả năngnằm trong rổ. Tuy nhiên khi tìm thì không có. Đây chính là một false positive.
Ứng dụng thực tế
Trong lĩnh vực công nghệ thông tin, BF được ứng dụng cực kỳ rộng rãi. Tuy nhiên, do đặc thù từng ứng dụng là khác nhau, mà cách cài đặt BF cho ứng dụng đó cũng khác nhau.
- Ví dụ với Bitcoin
- Ví dụ với Redis
Rõ ràng có sự khác nhau trong việc cài đặt hash function cho BF trong Bitcoin và Redis
Một số biến thể trong cuộc sống
Trong cuộc sống cũng có những ứng dụng, nếu xét về bản chất, thì rất liên quan đến ý tưởng của BF ở trên.
Ví dụ gần đây có tin đồn bệnh viện Xanh Lè cho trộn chung huyết thanh của bệnh nhân để xét nghiệm. Nếu nhìn dưới góc độ BF thì việc này không hẳn hoàn toàn là xấu.
Việc trộn chung mẫu máu (ví dụ của 3 người) chính là việc chọn hàm băm (hash function), và việc xét nghiệm trên máy ELISA chính là việc có chi phí tốn kém (“tốn kém” theo tiêu chí: Số lượng máy ELISA có hạn, người cần xét nghiệm đông, vậy nếu xét nghiệm từng người một, sẽ rất mất thời gian).
Với việc xét nghiệm chung 1 lần cho 3 người
- Nếu kết quả trả về là âm tính, nghĩa là cả 3 người đều không có bệnh => giảm số lần xét nghiệm từ 3 xuống 1.
- Nếu kết quả trả về là dương tính, nghĩa là 1 trong 3 (hoặc cả 3) có khả năng có bệnh => xét nghiệm riêng 1 lần nữa với nhóm 3 người này => nâng số lần xét nghiệm từ 3 lên 4.
- Tuy nhiên, phải để ý rằng, tỉ lệ người nhiễm bệnh là thấp hơn rất nhiều người không bệnh, nên nếu tính ra thì sự đánh đổi này là “có lời”
Mặc dù vậy, đây sẽ là tai hại, nếu
- Việc trộn chung mẫu máu làm ảnh hưởng tới độ chính xác của xét nghiệm. Ví dụ người có bệnh có tỉ lệ máu xấu (để phát hiện ra bệnh) trên tổng máu là 10% (người viết không rành về y, chỉ nói trên góc nhìn con số). Vậy 1 người nhiễm bệnh trộn với 2 người ko bệnh sẽ cho ra mẫu huyết thanh là 3.3%. Giả sử máy ELISA phát hiện với tỉ lệ máu xâú tối thiểu là 5%, vậy nghiễm nhiên người có bệnh sẽ đc chuẩn đoán là không bệnh.
- Việc gộp chung thế này có làm giảm chi phí xét nghiệm cho bệnh nhân không? Hay là 1 người xét nghiệm riêng cũng 1 chẹo, 3 người gộp chung mà vẫn mỗi người 1 chẹo?