#tech #summary #mysql #vi
TL; DR
- Cấu hình master-master trên nhiều node EC2
- Mỗi node có nhiều database, với schema giống hệt nhau.
- Thực hiện điều phối việc read/write bằng cách tạo UUID cho từng record.
- Sử dụng duy nhất column text blob data cho việc lưu mọi thông tin liên quan đến object dưới dạng JSON.
Background
Với ứng dụng web có traffic lớn thì việc scale là không thể tránh khỏi. Scale thì có thể tiến hành trên nhiều tầng, như tầng app, tầng db. Và theo mình thì scale ở tầng DB vẫn luôn là bài toán khó nhất. Vậy chúng ta cùng xem các kỹ sư tại Pinterest vì sao họ lại phải scale Mysql và họ đã thực hiện như thế nào.
Bài viết lược dịch từ Sharding Pinterest: How we scaled our MySQL fleet, một bài viết theo mình đánh giá là rất chất lượng, và có nhiều giá trị có thể tham khảo.
Mình sẽ ko dịch nguyên xi, mà sẽ đi vào nét chính là Why and How, 2 câu hỏi điển hình mỗi khi ta định thực hiện việc gì đó. Đồng thời mình sẽ giải thích/mở rộng luôn những chỗ có khó hiểu (với bản thân mình) khi vừa đọc lần đầu.
// Pinterest đã lauch architecture này từ đầu năm 2012, và hệ thống vẫn ngon cho tới bây giờ.
Why
Trước thời điểm tiến hành “cải tổ”, Pinterest có:
- Hơn 50 tỷ pin được pin vào khoảng 1 tỷ board (mỗi user có nhiều boards, mỗi board có nhiều pins), và có nhiều thông tin râu ria như repin, like pin …
- Họ đã dùng một số công nghệ NoSQL, và tất nhiên cả mô hình master-slave kinh điển nữa, nhưng tất cả vẫn ko đáp ứng đủ với lượng dữ liệu trên. Cái thì break, cái thì lỗi.
Vì vậy họ phải nghĩ tới 1 phương án mới, với các tiêu chí sau:
- Hệ thống phải ổn định, dễ vận hành, và dễ scale.
- Mọi thông tin mà Pinner (có thể hiểu là user) tạo ra phải đảm bảo có thể được accesss mọi lúc.
- Support việc query N pins trên một board đảm bảo theo 1 thứ tự cho trước (theo thời gian tạo pin hoặc theo 1 tiêu chí mà user đề ra)
- Nếu phải update, thì việc update phải là đơn giản nhất có thể.
Một số suy luận và định hướng mà họ nhận ra khi tiến hành sharding:
- Một khi đã shard, họ sẽ ko thể sử dụng joins, foreign keys, hoặc index một cách global được. (Vì data đã được chia thành các “cục” nhỏ, isolate với nhau). Tất nhiên, họ vẫn có thể sử dụng các chức năng này với data cục bộ.
- Load balancing vẫn là cần thiết sau khi shard. Không để trường hợp node này quá đầy, node kia lại ko có gì.
- Những nodes cần có tính ổn định cao.
- Một khi đã shard, thì ko sờ vào data ở slave nữa. Mọi action read/write đều tiến hành trên master hết.
- Cần 1 giải thuật đơn giản khi tạo UUID cho tất cả các records của họ.
Và họ quyết định sharding hệ thống MySQL theo cách của họ như dưới đây.
How
// Tại sao họ lại chọn MySQL mà ko phải nền tảng khác? Anh kỹ sư có nói trong bài viết là: Đừng đú theo công nghệ làm gì , hãy cứ right tool for right job :D
- Đầu tiên, họ bắt đầu với 8 con EC2, mỗi con EC2 (chạy một instance MySQL) lại có 1 con EC2 khác đi kèm, tạo thành 1 cặp với cấu hình master-master (ko phải là master-slave nữa), nhằm mục đích con master ko bị mất dữ liệu ngay cả khi nó bị tèo. // Nếu con master1 bị tèo, thì lập tức con đi kèm được cho lên làm master luôn. Sau khi con master1 khôi phục thì vai diễn lại đổi thành master1 làm backup cho con đi kèm, cứ như vậy …
Nói phải có sách, mách là phải có hình:
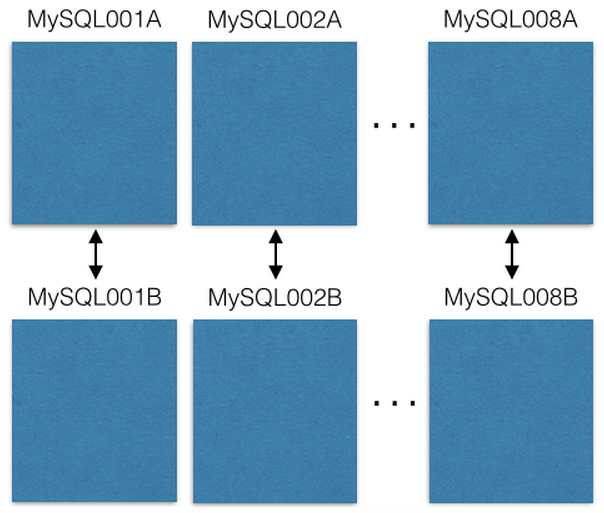
Và mọi thao tác read/write được thực hiện trên con master thôi, con đi kèm chỉ được dùng khi con master có vấn đề.
- Trong mỗi con EC2 có nhiều database. Mỗi database này là 1 shard, có schema structure giống hệt nhau
Lại hình:
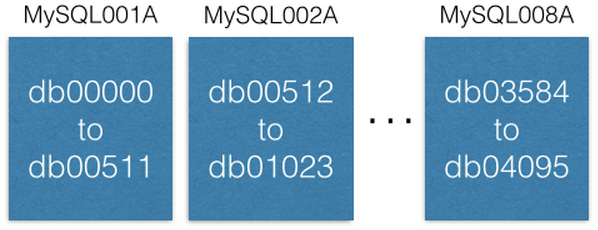
- Họ lưu cấu hình shard nào, có ID là bao nhiêu? con EC2 nào chứa shard nào? … vào ZooKeeper:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”},
{“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”},
...
{“range”: (3072, 3583), “master”: “MySQL007A”, “slave”: “MySQL007B”},
{“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]
// (0,511) tương ứng với db00000 to db00511 ở hình trên.
-
Tạo UUID (đoạn này mình nghĩ là đoạn hay nhất của film), để có thể phân phối data được viết vào các shard một cách chính xác và balance nhất: // Đoạn mình sẽ giải thích kỹ, để sau này mình có đọc lại cũng 1 phát hiểu luôn.
-
Họ tạo UUID là 1 số 64 bit, dùng cho mọi query từ bên ngoài vào, có cấu trúc:
UUID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
Với:
- shard ID: là 1 số 16bit, có vai trò là ID của shard.
- type ID: là 1 số 10bit, có vai trò chỉ ra
typecủaobject. Ví dụ nếu type ID = 1 có nghĩa object type là Pin, type ID = 2 ứng với object type là Board chẳng hạn. - local ID: là 1 số 36 bit, có vai trò là ID của records bên trong shard, có giá trị auto increment.
Từ công thức bên trên, có thể thấy UUID được tạo bằng cách:
(Dịch trái shard ID 46 bit) bitwise OR (Dịch trái type ID 36 bit) bitwise OR (Dịch trái local ID 0 bit)
// Dịch trái, dịch phải thì giống như việc kéo cái cửa trong nhà của tụi Nhật mà mình hay thấy trên film đó. Dịch trái thì kéo cái cửa sang trái, phần bên phải hở ra thì fill toàn bit 0 vào. Dịch phải là kéo cửa sang phải, các bit bị khuất thì bị xoá đi. Nói 1 cách khác, dịch trái làm tăng giá trị của số, dịch phải làm giảm giá trị của số.
// Dịch trái numberA x bit: là việc fill x bit 0 vào bên phải của numberA ở dạng nhị phân. Ví dụ: numberA = 3 (dạng nhị phân là 11), thực hiện dịch trái numberA 5 bit, ta thu 1100000.
// bitwise OR: thực hiện OR từng bit từ bên phải sang trái của 2 số dạng nhị phân. Nếu cả 2 bit là 0 thì bit thu được là 0, ngược lại bit thu được là 1. Ví dụ: 8 bitwise OR 22 = 1000 bitwise OR 10110 = 11110 = 30
// Do UUID là 1 số 64 bit, nên dù có dịch trái shard ID (có độ dài 16bit) 46bit đi nữa, thì cũng mới chỉ là 1 số 46 + 16 = 62 bit, vẫn dư 2 bit, và vẫn bảo đảm là ko số nào “dẫm” vào đuôi số kia, do số lượng bit dịch bằng tổng độ dài của các số phía trước rồi.
// Theo mình đánh giá thì đây là 1 cách băm cực hay. Nếu như băm theo kiểu lấy tổng, hay tạo string rồi lấy hash thì ko chính xác, do có nhiều case bị trùng nhau. Và hơn nữa cách này decompose cực đơn giản, khỏi key với kiếc làm gì, sẽ đc giải thích như bên dưới.
Nói thì khó tưởng tượng, đi vào thực tế luôn. Ví dụ với URL:
https://www.pinterest.com/pin/241294492511762325/, thì UUID nhận được là 241294492511762325., sẽ được decompose cái UUID theo cách sau:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429
Type ID = (241294492511762325 >> 36) & 0x3FF = 1 // type Pin -> query vào table pins
Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
Từ công thức trên, có thể thấy được:
- Shard ID được decompose từ việc dịch phải 46bit UUID, sau đó bitwise AND với 0xFFFF (hay là 0b1111111111111111). Nghĩa là cắt đúng vị trí của Shard ID được dịch trái ở công thức tạo UUID bên trên. Trong trường hợp này thì việc bitwise AND với 0xFFFF là hơi thừa. Tuy nhiên nó lại có ích nếu như Shard ID ko còn đứng ở phía bên trái nhất của 64bit UUID nữa.
- Type ID và Local ID được decompose tương tự, và cần phải bitwise AND tương ứng với 1 số 10bit và 1 số 36bit toàn 1. Như vậy là mọi thông tin cần thiết đã được decompose một cách toàn vẹn, mà lại còn nhanh nữa chứ. Tính toán trên bit mà.
// Bitwise AND: thực hiện AND từng bit từ bên phải sang trái của 2 số dạng nhị phân. Nếu cả 2 bit là 1 thì bit thu được là 1, ngược lại bit thu được là 0. Ví dụ: 8 bitwise AND 22 = 1000 bitwise AND 10110 = 00000 = 0
// Anh kỹ sư nghĩ ra cái trò này có kinh nghiệm với compiler và chip design. Thế mới thấy mấy cha computer science đi thiết kế thì khác bọt thế nào.
Sau khi đã có đầy đủ thông tin, chỉ việc query:
conn = MySQLdb.connect(host=”MySQL007A”)
conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
// Host MySQL007A được nhặt ra từ shard ID 3429, có range nằm trong {“range”: (3072, 3583), “master”: “MySQL007A”, “slave”: “MySQL007B”}, nên nó chọn host MySQL007A để query thôi.
-
Cấu trúc dữ liệu:
- Họ phân loại dữ liệu ra 2 loại: Object và Map. Nói nôm na là các table có tính chất là chứa thông tin, và các table có tính chất là tham chiếu. Ví dụ: Pin và Board là kiểu Object, còn board_has_pin là kiểu Map.
- Ví dụ với table Pin:
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE- Để ý thấy là table Pin có bao nhiêu thông tin như thế, vậy mà sao lại có mỗi column data ? Cái hay là họ nhét tất cả các thông tin liên quan đến pin vào column data này, dưới dạng JSON:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
Tại sao? Vì giả sử nếu phải thêm 1 column mới cho 1 table theo cách tiếp cận cũ, thì việc alter table sẽ rất nặng (do phải alter cho tất cả các table tương ứng của các shard). Tuy nhiên với cách làm này, thì khỏi cần alter gì cả, chỉ cần khai báo ở tầng app giá trị default cho column mới mỗi khi muốn đọc ra thôi. Pinterest hơn 3 năm rồi (tính tới thời điểm bài gốc được đăng) chưa từng phải alter table!
- Khi insert 1 record mới, họ chỉ định ghi nó vào shard ID nào, type ID là gì. Sau khi record được insert rồi, nó sẽ trả về local ID, lúc này sẽ kết hợp với Shard ID và Type ID để cho ra UUID theo cách bên trên. Quá lợi hại.
- Còn với table dạng Map thì có cấu trúc như này:
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;board_idvàpin_idlà các UUID 64bit như trên, sequence có dạng timestamp, bảo đảm cho việc order theo created time rồi.// Câu hỏi phát sinh: Vậy giả sử có query: lấy tất cả boards của user X, thì ko lẽ query trên tất cả các shards à? Mình dự là không. Đơn giản là có table users, trong column data có chứa luôn list board rồi. Vì là JSON mà, nó lưu gì chả được. Tiếp cận theo cách của NoSQL là hoàn toàn đúng đắn trong trường hợp này.
// Bài viết lược dịch đoạn gây cấn nhất trong phim rồi. Bài gốc vẫn còn 1 đoạn nhắc tới 3 cách scale (scale cấu hình - nâng cấp sức mạnh cho EC2 instance, scale thêm EC2 instance bằng cách tăng số thứ tự của shard ID, và scale thêm instance bằng cách chia nhỏ range của shard ID), và 1 đoạn nhắc tới làm sao map others ID tới pinterest ID nữa, nhưng mình lười, dành phần này cho bạn đọc :))
//P/S: Mấy lời tâm sự cuối bài của anh kỹ sư cũng hay.
Kết luận:
Mấy anh to lúc nào cũng đẳng cấp.